Debug PLEG is not healthy 问题
背景:
测试服更新完1.22.1版本之后。work节点状态一直处于Ready和NotReady循环。
环境:
- kubernetes version:
v1.22.1 - systemd version:
219-78.el7_9.3.x86_64 - centos7.6:
3.10.0-957.21.3.el7.x86_64 - docker version:
20.10.7
什么是PLEG?
PLEG(Process Group and Event Monitor)是Kubernetes节点上的一个组件,用于监视节点上容器的状态并保持同步。
为什么会出现PLEG is not healthy:
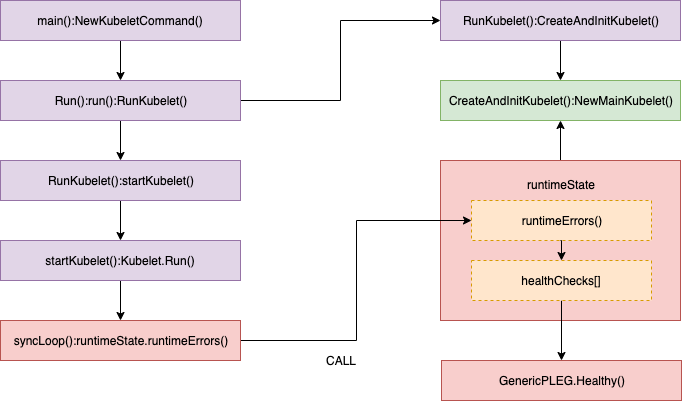
Kubelet 定期在 SyncLoop() 中调用 Healthy() 函数,以检查 PLEG 是否健康。
Healthy() 函数会检查 relist 进程(PLEG 的关键任务)是否在 3 分钟内完成。这个函数被添加到 runtimeState 中,命名为 “PLEG”,默认情况下会每隔 10 秒定期调用。如果 relist 进程的完成时间超过 3 分钟,就会通过堆栈报告“PLEG is not healthy”问题。
通过日志查看错误信息:
查看节点状态,确认具体存在问题的节点
1 | [root@k8s-master opt]# k get node -w |
查看节点具体错误信息 PLEG is not healthy: pleg was last seen active 3m53.912072577s ago; threshold is 3m0s
1 | [root@k8s-master opt]# k describe node k8s-node-1 |

或者登陆至节点上查看 tailf /var/log/messages & journalctl -u kubelet
1 | Mar 1 15:52:28 k8s-node-1 kubelet: E0301 15:52:28.477667 3031 kubelet.go:1991] "Skipping pod synchronization" err="PLEG is not healthy: pleg was last seen active 3m0.195184382s ago; threshold is 3m0s" |
确认导致PLEG-is-not-healthy的原因:
在Kubernetes中,kubelet启动时会调用Systemd API来检查节点上各个容器的状态,并将其报告给Kubernetes控制平面。具体来说,kubelet会在启动时连接到Systemd守护进程(systemd daemon),并监听systemd的D-Bus接口。然后kubelet就可以通过D-Bus接口调用systemd提供的API,比如查询容器状态、停止、重启等操作。
在kubelet中,PLEG(Pod Lifecycle Event Generator) 会定期检查Pod中的容器是否健康。当发现容器不健康时,会产生相应的事件通知给kubelet处理。PLEG会通过调用Systemd的API来查询容器的状态,如果发现Systemd的cookie值溢出,就会产生“PLEG is not healthy”错误,从而影响容器的健康状态。
首先在问题节点安装gdb 和 systemd debuginfo:
1 | #systemd-debuginfo包必须和systemd版本一一对应。否则可能一堆问题。。 |
然后使用命令把 gdb attach 到 systemd
1 | [root@k8s-node-1 ~]# gdb /var/lib/systemd/systemd <pid> |
在函数sd_bus_send 设置断点
1 | (gdb) break sd_bus_send |
继续执行
1 | (gdb) continue |
用p /x bus->cookie 查看对应的cookie值
1 | (gdb) p /x bus->cookie |
判断此值超过0xffffffff
就证明cookie溢出,必然会导致节点NotReady
怎么判断呢。交给chatgpt发挥吧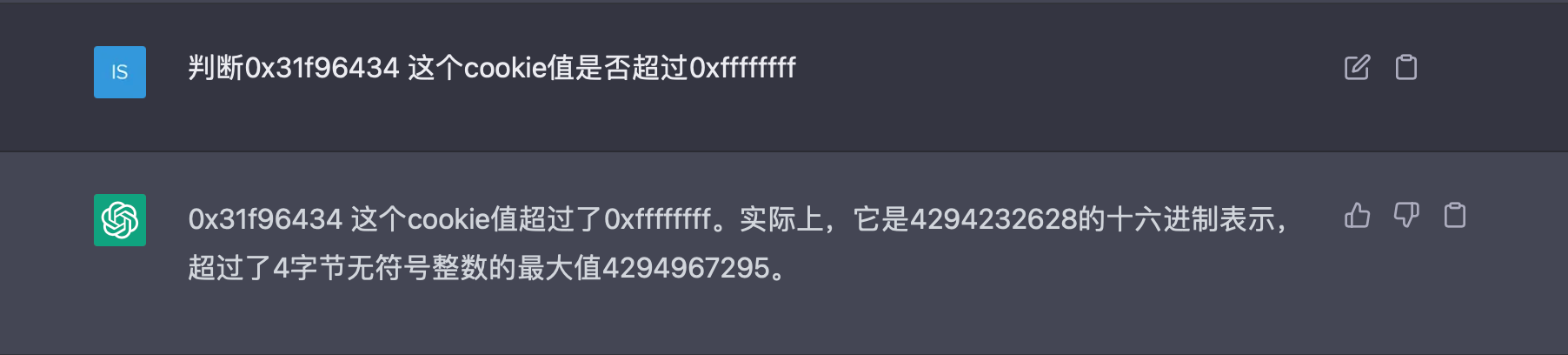
确认了cookie溢出之后就可以使用 quit 来 detach 调试器
解决cookie溢出问题:
更新systemd
1 | yum update -y systemd && systemctl daemon-reexec |
tips:systemctl daemon-reexec用于重新启动systemd进程,同时将新的systemd二进制文件加载到内存中,以确保在不需要重启系统的情况下使用新的systemd版本。执行此命令将使systemd重新加载其所有配置文件并重新启动所有单元。
升级完systemd之后最好重启下节点的docker和kubelet进程。再次查看节点上的日志。发现PLEG已经不存在了。并且节点Ready状态稳定。
参考:
Node flapping between Ready/NotReady with PLEG issues
Pod Lifecycle Event Generator: Understanding the “PLEG is not healthy” issue in Kubernetes
PLEG is not healthy - Ubuntu 20.04 - runc issue
Make Kubernetes batch system deal with pods that can’t be deleted
kubelet: do not cleanup volumes if pod is being killed
relist in kubernetes/pkg/kubelet/pleg/generic.go